用 Claude Opus 4.7 最新 benchmark 图,一次看懂 AI benchmark 指标
2026 年 4 月 16 日,Anthropic 正式发布了 Claude Opus 4.7。和每次大模型发布一样,最先刷屏的往往不是参数表,而是一张 benchmark 成绩图。
这次也一样。很多人第一眼看到的,是几个醒目的分数:SWE-bench Pro 64.3%、SWE-Bench Verified 87.6%、Terminal-Bench 2.0 69.4%、OSWorld-Verified 78.0%。但真正有信息量的,不是“哪个数字最大”,而是这些 benchmark 名字本身。
因为它们测的不是同一种能力:有的在测真实软件工程,有的在测终端执行力,有的在测网页搜索,有的在测电脑操作,还有的在测金融分析、安全漏洞复现和多模态推理。
如果不先把这些指标看懂,很容易把图读歪。比如把 91.5% 的 MMMLU 直接理解成“整体实力一定强于 64.3% 的 SWE-bench Pro”,这就是典型误读。本文的主线很简单:不讨论跑分党式的谁高谁低,而是借 Anthropic 今天发布的这张 Claude Opus 4.7 benchmark 图,把常见 AI benchmark 指标逐项讲清楚。
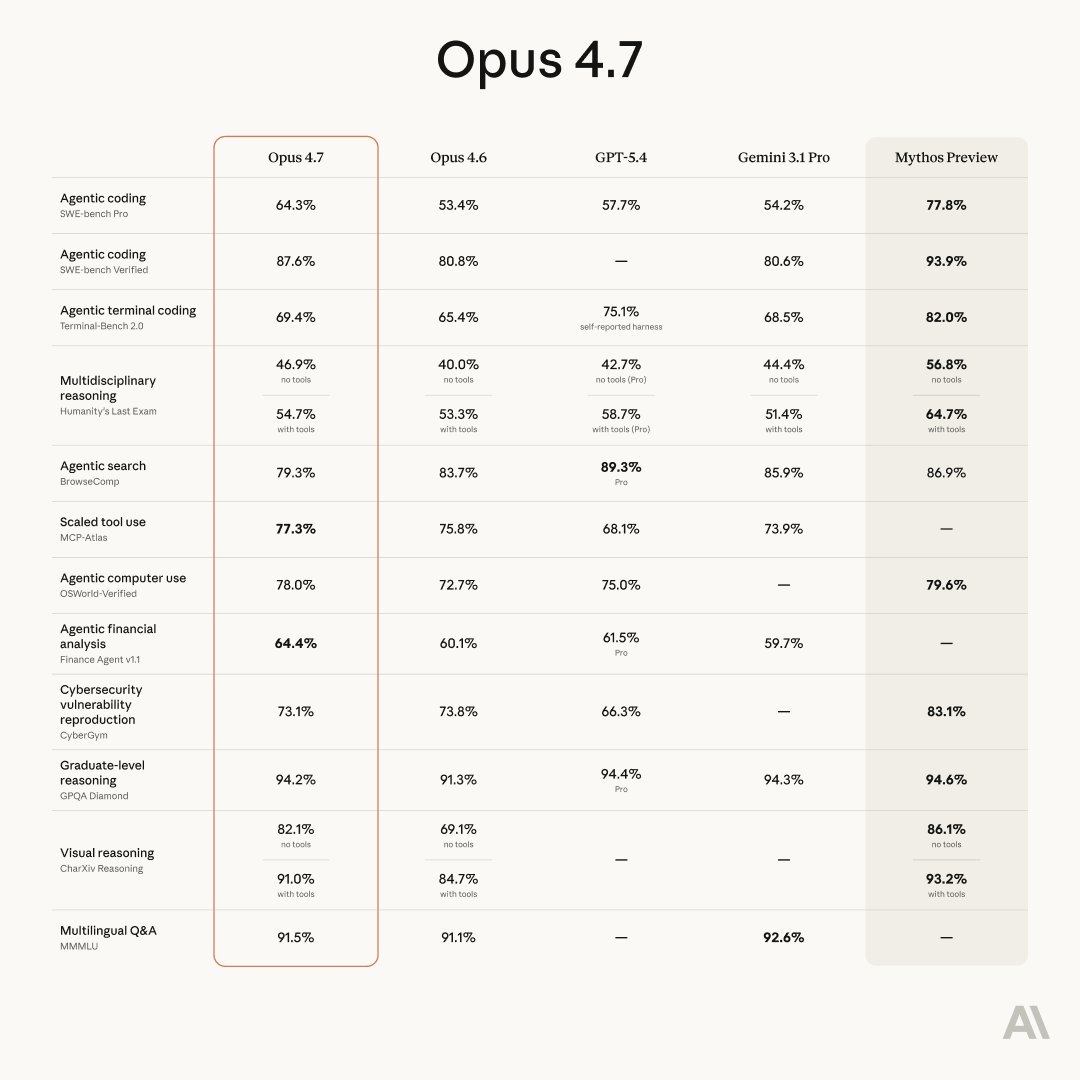
Anthropic 已经正式发布了 Claude Opus 4.7 及其 benchmark。
这张图最容易看错的地方
先记住 4 个原则:
- 每一行都是一个独立 benchmark,不能把不同行的百分比直接横向比较。
- 有些 benchmark 测的是“回答对不对”,有些测的是“任务有没有真的做完”。
with tools和no tools是两个不同档位,不能混着看。- 图里的小字同样重要,像
Pro、Verified、self-reported harness都会影响含义。
先补一句:下面说的“分值怎么算”,指的是这些 benchmark 的标准公开计分逻辑。Anthropic 这张图并没有逐项公开完整的评测 prompt、agent scaffold、采样次数和投票策略,所以更稳妥的理解方式是:先搞清楚每个 benchmark 的公开判分规则,再把图里的百分比理解成在该规则下得到的成绩。
下面这张表,可以先帮你建立一个整体印象。读的时候不要把它当成“统一考试总分表”,而要把它看成一张能力地图:
| 图中指标 | Opus 4.7 分数 | 主要在测什么 | 这个分数更接近什么含义 | 分值通常怎么算 |
|---|---|---|---|---|
SWE-bench Pro | 64.3% | 真实软件工程修复 | 问题解决率 | resolved 任务数 / 总任务数 |
SWE-Bench Verified | 87.6% | 真实 GitHub issue 修复 | 问题解决率 | resolved 任务数 / 总任务数 |
Terminal-Bench 2.0 | 69.4% | 终端环境中的工程执行 | 任务完成率 | 通过 checker 的任务数 / 总任务数 |
Humanity's Last Exam | 46.9% / 54.7% | 超高难跨学科推理 | 准确率 | 答对题数 / 总题数 |
BrowseComp | 79.3% | 网页搜索与检索 | 准确率 | 语义匹配正确答案的问题数 / 总题数 |
MCP-Atlas | 77.3% | 外部工具调用与工作流 | 任务完成率 | 按 claims rubric 统计覆盖度或 pass rate |
OSWorld-Verified | 78.0% | GUI 电脑操作 | 任务完成率 | 终态通过执行评测脚本的任务数 / 总任务数 |
Finance Agent v1.1 | 64.4% | 金融分析 agent | 任务完成率/判定正确率 | 私有任务集逐题判分后的平均准确率 |
CyberGym | 73.1% | 漏洞复现 | 漏洞复现成功率 | 成功复现漏洞的实例数 / 总实例数 |
GPQA Diamond | 94.2% | 研究生级科学问答 | 准确率 | 多选题答对数 / 总题数 |
CharXiv Reasoning | 82.1% / 91.0% | 科研图表理解与推理 | 准确率 | 推理题答对数 / 总题数 |
MMMLU | 91.5% | 多语言知识与推理 | 准确率 | 多语言多选题答对数 / 总题数 |
1. SWE-bench Pro:看模型能不能像工程师一样修真实仓库
这是 Opus 4.7 这张图里最值得先看的指标之一,分数是 64.3%。
SWE-bench Pro 测的不是刷题,而是把模型放进真实开源项目的上下文里,让它读 issue、读代码、改代码、跑测试,最后看它到底有没有把问题修好。它关心的是完整的软件工程链路,而不是单点代码生成。
为什么这个指标重要?因为它更接近今天大家真正关心的 agentic coding:
- 能不能在大仓库里定位问题
- 能不能跨多个文件完成修改
- 能不能理解测试失败的原因
- 能不能把补丁做到“真的可用”
如果你想知道 Opus 4.7 是否真的更像一个能干活的编程 agent,这一行的参考价值很高。
分值怎么算? SWE-bench Pro 的公开主指标是 Resolve Rate。一条任务只有在模型给出补丁后,评测环境确认这个 issue 被真正解决时,才算 resolved。最常见的公开判定逻辑,是看补丁是否让原本该通过的测试继续通过,同时让原本暴露问题的测试转为通过。最终分数就是:
resolved 的任务数 / 总任务数
所以 64.3% 这种数字,本质上不是“代码写得像不像”,而是“这批真实工程问题里,有多少最终被修成了”。
2. SWE-Bench Verified:经典的真实 issue 修复基线
这一项 Opus 4.7 的分数是 87.6%。
SWE-Bench Verified 来自 SWE-bench 体系里的人工筛选子集,重点是把不清晰、不可解或者评测噪声太大的样本剔掉,让结果更稳定。它依然是在测真实仓库里的问题修复,只是样本集更“干净”。
它和 SWE-bench Pro 的区别可以简单理解成:
SWE-Bench Verified更像成熟、标准化、历史可比性强的编码 benchmarkSWE-bench Pro更像更难、更贴近新一代 agentic coding 场景的 benchmark
所以这两行不是重复的。前者适合看“在经典公开基线上表现如何”,后者适合看“在更真实、更复杂的工程环境里表现如何”。
分值怎么算? SWE-Bench Verified 的计分逻辑和 SWE-bench 主体系是一致的,也是看 resolved rate。区别不在于算法变了,而在于数据集换成了人工验证过的 500 个实例。也就是说,最后这个百分比仍然是:
resolved 的任务数 / 500
判断标准仍然是补丁是否真的把问题修掉,而不是只看模型有没有输出一段像样的代码。
3. Terminal-Bench 2.0:看终端执行力,而不只是代码生成
这一项 Opus 4.7 的分数是 69.4%。
Terminal-Bench 2.0 测的是模型在真实终端环境里能不能把任务完成。它会涉及查目录、读日志、装依赖、跑命令、编辑文件、调试失败原因等一整串动作。
这个 benchmark 的价值在于,它能暴露很多“代码看起来会写,但事情做不完”的问题,比如:
- 命令用错
- 环境修坏
- 没有根据输出继续调整
- 改完后不会验证
因此这行更像在测:Opus 4.7 在命令行里是不是一个可靠的执行者。
分值怎么算? Terminal-Bench 2.0 的核心不是人工主观打分,而是任务级 checker。每个终端任务都会配套可执行的校验逻辑,去检查最终容器状态、文件结果、命令输出或环境配置是否满足目标。最终分数可以理解为:
通过 checker 的任务数 / 总任务数
所以这类百分比更像“任务成功率”,不是普通问答意义上的“答对率”。
4. Humanity’s Last Exam:高难度跨学科推理
这一项图里给了两档结果:
no tools是46.9%with tools是54.7%
Humanity's Last Exam 通常简称 HLE。它不是通识问答,而是非常难的跨学科问题集,覆盖数学、物理、化学、生物、医学、人文等领域,更像在考前沿模型的深度推理能力。
这行最值得看的点,不只是分数本身,而是 with tools 比 no tools 更高。这说明 Opus 4.7 不只是“想得出来”,还更擅长借助工具把复杂问题做稳。
分值怎么算? HLE 由多选题和可自动评分的简答题组成。公开论文对它的描述很明确:它是为了自动化评分设计的高难题集。因此最直接的理解就是:
- 多选题:选对算对
- 简答题:答案与参考答案做自动比对,匹配算对
最后的分数,就是答对题数占总题数的比例。with tools 和 no tools 的差别,不在评分器,而在模型答题时能不能借助工具。
5. BrowseComp:看它会不会上网找答案
这一项 Opus 4.7 的分数是 79.3%。
BrowseComp 测的不是死记硬背,而是浏览型 agent 的检索能力。题目通常不是搜一下就能出答案,而是需要反复改关键词、打开多个网页、交叉验证信息之后,才能把结论找出来。
所以这项分数高,说明模型更像一个会查资料的研究助理,而不只是一个靠训练记忆回答问题的聊天机器人。
分值怎么算? BrowseComp 的公开论文里有一个很关键的细节:它的参考答案通常就是一个很短的字符串,因此评分时不是让人一题题人工审,而是用 AI grader 去判断模型最终答案和参考答案是否语义等价。换句话说,它不是按“浏览过程有多漂亮”计分,而是按:
语义匹配参考答案的问题数 / 总问题数
所以 79.3% 本质上还是正确率,只不过前面那段“找答案”的过程非常难。
6. MCP-Atlas:看工具调用和多步工作流
这一项 Opus 4.7 的分数是 77.3%。
MCP-Atlas 的重点在于真实工具调用。它看的是模型能不能通过 MCP 把多步任务串起来,例如先查数据、再过滤、再写入、再触发后续动作。
它关心的不是“知不知道有这个工具”,而是:
- 能不能选对工具
- 能不能给出正确参数
- 能不能把工具调用串成完整工作流
- 中途失败时能不能修正
因此 MCP-Atlas 高,通常意味着这个模型更适合用来做真正的企业工作流 agent。
分值怎么算? MCP-Atlas 是这张图里最容易被误读的一项,因为它的公开方法不是简单的二元成败。官方论文写得很明确:它使用 claims-based rubric,也就是先把一个任务拆成若干应该满足的事实性 claim,再看模型最终答案满足了多少条。公开结果通常至少会看两种数字:
Pass Rate:任务是否整体通过Mean Coverage:所有 claim 里满足了多少比例
所以像图里这种单独给一个 77.3% 的写法,如果官方没有额外标注,你最好不要武断地把它理解成纯粹的“成功率”。更稳妥的理解是:它反映了模型在多步 MCP 工具工作流里的整体完成质量。
7. OSWorld-Verified:看模型能不能真的操作电脑
这一项 Opus 4.7 的分数是 78.0%。
OSWorld-Verified 属于典型的 computer use benchmark。它把模型放进接近真实桌面环境的系统里,要求它通过点击、输入、切换窗口、滚动页面等动作完成多步 GUI 任务。
这个指标很适合衡量:
- 是否能理解界面状态
- 是否能定位正确控件
- 是否能在多步操作里不走偏
- 是否真的能把电脑上的事情做完
如果你更关心“AI 能不能替我操作浏览器和应用程序”,这行往往比传统问答 benchmark 更有参考价值。
分值怎么算? OSWorld-Verified 的官方描述强调的是 execution-based evaluation。也就是说,每条 GUI 任务都有自定义的执行评测脚本,去检查最终系统状态,而不是只看屏幕截图像不像。最终分数可以理解为:
终态通过评测脚本的任务数 / 总任务数
这也是为什么 OSWorld 的分数往往更像“真实任务成功率”,而不是视觉问答准确率。
8. Finance Agent v1.1:看金融分析场景里的真实任务能力
这一项 Opus 4.7 的分数是 64.4%。
Finance Agent v1.1 不是传统学术 benchmark,而更像一个垂直领域评测。它衡量模型能不能完成一类真实金融分析任务,例如查财报、提取关键数字、做简单估算和对比,最后输出结构化结论。
它告诉你的不是“模型是不是全能第一”,而是:在投研和金融分析这种具体工作流里,Opus 4.7 是不是更像一个能完成任务的 agent。
分值怎么算? Finance Agent v1.1 来自 Vals AI 的私有 benchmark。Vals 公开说明里提到,它们的 benchmark 以 accuracy 为核心,但具体检查方式可能是两类:
strict accuracy checkrubric-based LLM-as-a-judge
最终分数是逐题得分后的平均准确率,并配标准误差。由于 Finance Agent v1.1 的任务集和详细 rubric 并不是完全公开的,所以这类分数最准确的理解是:第三方私有金融任务集上的任务准确率,而不是像 MMLU 那样人人都能完全复现的一组公开选择题成绩。
9. CyberGym:看漏洞能不能复现出来
这一项 Opus 4.7 的分数是 73.1%。
CyberGym 测的是安全领域里的实际执行能力。它不是考模型背安全术语,而是看它能不能根据漏洞描述、代码仓库和运行环境,把漏洞真的复现出来。
这个 benchmark 通常要求模型同时具备:
- 代码理解能力
- 系统理解能力
- 安全分析能力
- 动手执行能力
所以这项分数高,往往说明模型在安全研究和漏洞分析场景里更强。
分值怎么算? CyberGym 的核心任务是让 agent 生成 PoC 去复现真实漏洞。公开论文把主指标直接写成 reproduction success rate。也就是说,一条实例只有在 PoC 真正成功触发目标漏洞时才算成功;很多实现里还会进一步要求它能区分 pre-patch 和 post-patch 版本。最终分数就是:
成功复现漏洞的实例数 / 总实例数
因此这类分数比“会不会讲漏洞原理”严格得多,它测的是能不能把漏洞实际打出来。
10. GPQA Diamond:研究生级科学问答
这一项 Opus 4.7 的分数是 94.2%。
GPQA 的全称是 Graduate-Level Google-Proof Q&A,核心思想是让题目不是靠简单搜索就能解出来,而是需要扎实知识和多步推理。Diamond 是其中最常被拿来对比的高质量子集。
这项 benchmark 更偏:
- 高难科学知识
- 多步推理
- 抗表面记忆
它能说明 Opus 4.7 在高难理科推理上很强,但它不是 agent 执行力 benchmark,不能直接拿来替代 SWE-bench 或 OSWorld。
分值怎么算? GPQA Diamond 本质上还是多项选择题 benchmark。公开论文说明 GPQA 是由专家编写的高难四选一题集,而 Diamond 是其中最常用的高质量子集。所以它的分数计算很直接:
答对的多选题数 / 总题数
随机乱猜的基线大约是 25%,因此像 94.2% 这种数字就意味着在这组题上接近“极高准确率”。
11. CharXiv Reasoning:看懂科研图表,而不是只会看图说话
这一项也给了两档结果:
no tools是82.1%with tools是91.0%
CharXiv Reasoning 的样本来自 arXiv 论文里的真实图表。它测的不只是“能不能描述图片”,而是能不能真正理解坐标轴、图例、曲线关系、趋势变化,再根据这些信息完成推理。
这行可以帮助你判断 Opus 4.7 的多模态能力到底强在哪里:不是单纯识图,而是能不能把图表当作结构化信息源来推理。
分值怎么算? CharXiv 官方项目页明确写了两件事:一是 Reasoning 是其中单独的一类问题,二是它们公开的分数是 accuracy,并且提供了用 GPT API 进行答案评分的评测脚本。因此更准确地说,这里的分数是:
在 Reasoning 子集上,被 grader 判为正确的回答数 / 总题数
所以 82.1% / 91.0% 仍然是正确率,只不过评分不是简单字符串完全相等,而是结合 reference answer 的自动判分。
12. MMMLU:看多语言场景下知识和推理有没有掉队
这一项 Opus 4.7 的分数是 91.5%。
图里写的是 MMMLU。可以把它理解成面向多语言场景的 MMLU 扩展评测,核心问题是:模型离开英文以后,在中文、日文、德文、阿拉伯文等不同语言里,知识理解和推理能力还能不能稳定保持。
这个指标对中文用户尤其重要。因为很多模型英文表现很好,但一到非英文场景就开始下滑。MMMLU 的意义,就是帮助你判断这种跨语言稳定性。
分值怎么算? MMMLU 本质上是多语言版本的 MMLU。公开资料通常把它描述为:把 MMLU 的多学科多选题扩展或翻译到多种语言,然后看模型在这些语言里的作答正确率。因此最直接的理解方式就是:
多语言多选题答对数 / 总题数
如果进一步拆开看,很多实现还会先算每种语言、每个学科的准确率,再汇总成整体分数。但无论如何,它的核心还是“多语言场景下的多选题准确率”。
读完这张图,应该得到什么结论
如果把 Claude Opus 4.7 这张图拆开看,会发现它真正想传达的不是单一能力,而是一组能力画像:
SWE-bench Pro、SWE-Bench Verified、Terminal-Bench 2.0在强调编码与终端执行BrowseComp、MCP-Atlas在强调搜索和工具调用OSWorld-Verified在强调真实电脑操作Finance Agent v1.1、CyberGym在强调垂直领域 agentGPQA Diamond、HLE、CharXiv Reasoning、MMMLU在强调知识、推理和多模态理解
对读者来说,更重要的收获也不是“谁第一”,而是:以后再看到模型发布时那种密密麻麻的 benchmark 图,你大概能立刻分清楚哪些是在测编码,哪些是在测 agent,哪些是在测推理,哪些根本不能横向比较。
换句话说,这篇文章真正想解决的问题是:AI benchmark 每个指标到底是什么意思。 而 Claude Opus 4.7 今天这张图,只是一个非常合适的切入口。
参考资料
- Introducing Claude Opus 4.7
- SWE-bench Leaderboard
- SWE-bench Verified
- Introducing SWE-bench Verified
- SWE-bench Pro Public Leaderboard
- Terminal-Bench
- Introducing Terminal-Bench 2.0 and Harbor
- Humanity’s Last Exam
- Humanity’s Last Exam paper
- BrowseComp: a benchmark for browsing agents
- Open-Sourcing MCP-Atlas: A Benchmark for Real Tool Use
- OSWorld
- Welcome to OSWorld!
- Vals AI
- About Vals Benchmarks
- CyberGym GitHub
- CyberGym paper
- GPQA paper
- CharXiv project
- CharXiv paper
- MMLU paper