服务器超时时间和请求队列大小设置
服务器超时时间和请求列表大小关乎程序的健壮性。设置过小,会导致有效的请求被丢掉。 设置过大,严重的情况下会引起雪崩。
超时
很多后台码农对超时时间的设置都没什么概念,特别是刚毕业的后台码农。 一般都是参照前人的代码,设置一个相同的超时,而且一般都是比较大的超时,只要程序能跑就没问题了。
后台服务基本上要设置两个超时,一是去请求其他服务时设置的超时,我们称之为请求超时时间, 一是对整个请求的处理超时,我们称之为处理超时时间。
一般后台服务都会请求后端服务去取数据的操作,这时需要设置一个超时,当达到超时时, 后端服务还没回包,则把当前的请求设为失败的请求。我们不能一直等到后端回包, 假如后端服务出问题了,一直不回包,那么当前的处理就会一直在等待。如果是同步请求, 那么当前的处理线程就会一直卡在那里,处理不了队列的其他请求了。
收到一个请求进行处理时,对其打上设置超时的计时器。如果超时了,直接给客户端返回超时。 客户端请求我们的服务器时,同样会应用到上面的请求超时设置,客户端会设置自己的请求超时。 如果我们没有对这个请求的处理设置超时,或者设置不合理,在客户端上,当前处理已经超时, 这时我们才处理完成回包,这个回包给到客户端就会被丢弃了。
那么我们要怎么设置超时呢。
对于请求超时时间,在后端服务正常的情况下,我们观察发起请求到收到响应所需要花的平均时间。 在这个平均时间上设置高一点的时间为超时时间。假如,后端服务的平均超时为100ms, 那么我们可以设置150ms的超时。
对于处理超时时间,我们先来看一下同步模型的处理,异步模型我们在后面再讨论, 我们观察整个处理过程所需要的平均耗时(cost_time)。 对于请求在队列中等待到处理的时间称为等待时间(wait_time)。 队列长度为n,则最大超时时间应该设置为:(n-1)*wait_time+cost_time+调高的值。
设置的处理超时,一般还要比客户端的请求超时低。不会就会出现上面说的丢弃响应包的情况。 通常,我们在假设处理超时设置合理的情况下,请求超时要根据处理超时时间来进行设置。
链路传输耗时
对于请求超时,如果是跨IDC、跨地域调用的话,我们还需要考虑数据的传输时间。
假如一个IDC在广州,一个在北京。两地距离2000km,通过内网专线进行通信。传输速度以光速计算,
传输一次需要(200010^3)/(310^8),约等于7ms。使用TCP通信,需要先握手再进行传输。
通信过程如下:
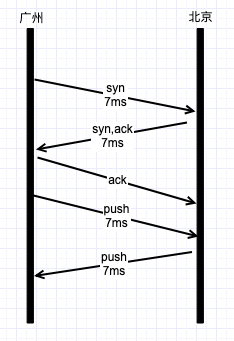
大概需要30ms左右,再加上折射,可能要加多40ms的传输耗时,这在请求耗时中占比是比较大的。 所以在考虑跨机房距离比较远的时候,如果根据后端的处理耗时来设置请求耗时时,需要考虑传输耗时。
请求队列大小
一般情况下,我们的服务会设置一个请求列队来缓存请求的数据,worker从列队里取数据进行处理。
如果队列设置太小,可能服务器还没饱和,就直接把请求拒绝了,降低了我们服务器的处理能力。 假如我们只有一个worker使用进行同步模型进行处理请求,每个请求请求处理10ms,处理超时设置为2000ms, 那么2000ms可以处理200个请求。但是队列只设置100个buffer,那么第101个包过来的时候直接响应队列满的错, 这就把处理能力降低了一半。
如果队列太大,客户端等待时间会过长,如果再加上超时设置不合理,则有可能会引起雪崩。
假设我们只有一个worker使用同步模型进行处理请求,每个请求平均需要100ms的耗时。 假如我们设置的处理超时为2000ms。队列长度设为21。 当请求压力上来的时候,队列一下子就被压满了,而且队列每移走一个,就会有一个请求进来, 这样,队列永远都是满的。对于队列中的第n个包(入队时的位置),则需要等待前面n-1个处理完, 等待时间为(n-1)*100ms,再加上处理耗时为100ms,则总耗时为(n-1)100+100ms=n100ms。 所以刚开始入队的第21个,耗时需要2100ms,已经超时了,所以处理完后就已经超时了。 对于所有入队位置在第21的请求,最后都是超时的。我们设置的情况是请求压力比较大, 也就是说队列会一直都是满的。所以所有的包计算处理都是浪费资源。
综合以上两个例子,对于同步模型,不能忽略处理超时时间的设置来设置请求队列的大小。
异步模型
对于异步模型,在io的时候,workder可以调度去处理其他的请求,这样可以加大服务的吞吐量。 我们可以把队列的大小调高,当处理到io的时候,就去处理拿下一个请求来进行处理。但是, 这样做的会把很多请求都往io的对端去,如果对端是一个服务,这样会把压力压到对端去, 所以对端也要做好耗时和队列的设置,以免把对端压死。异步模型的队列大小,我们逐步调整队列的大小, 对服务进行压测,让服务的cpu达到瓶颈,然后把队列设置到比此值稍大即可。因为是异步处理。
同样的,对于异步模型,所有的io时间都不会把请求阻塞住了。所以,对于异步模型, 我们只要把处理超时设为平均耗时加上调高的值即可。